oleg.milantiev.com
Сайт Олега Милантьева
Не беда, если не понял название целиком. И не так плохо, если понял лишь часть. Отлично, если давно и крепко в теме! А тема у меня сегодня быстрый поиск объектов на изображении или видео.
Было / стало:


Я не зря выделил жирным слово «быстрый». Это и есть тема текста. Буду говорить о том, как ускорить детектор на микрокомпе Orange Pi 3B, снабжённым нейросопроцессором RK3566. Ну и как применить это к фреймворку Robot Operation System (ROS2) для изменения поведения робота в зависимости от найденных объектов.
Искать можно не только лица, как в примере. Можно монетки, машинки, компьютерные мышки или чайные чашки. Можно искать что угодно. На цветном изображении 640х640 можно одним махом найти один или сотню объектов. За считанные секунды … или миллисекунды? Важный вопрос, если хочется построить робота, который в реалтайме обнаружит объект и изменит своё поведение в зависимости от результатов поиска.
YOLOv8 (https://www.ultralytics.com/ru) — весьма точная и быстрая нейронка. На серьёзном компе и без оптимизаций работает очень шустро. Есть пять версий размера модели. Соответственно и пять скоростей / точностей. Чем медленее работает вариант, тем точнее, что логично.
Сеть многофункциональная, направленная на распознавание элементов на фото / видео. Может заниматься детектированием, поиском, сегментированием и определением позы. Установка на CPU простая. Тестовое использование не сложное. Я уже применял классификатор в моём проекте AllSky камеры. Нейросетка определяет ясно ли на небе или облачно. Здесь подробности.
Как любая нейронная сеть, YOLO, при запуске на CPU, потребляет много ресурсов (памяти и процессора). При редком запуске, занятый на миллисекунды проц и гиг памяти на x64 обычно не проблема. Но чем больше задач детекции, чем слабее комп, тем ощутимей необходимость оптимизации. Уже привычно запускать нейронки на GPU (видеокарте) или на специальном устройстве ускорения нейросетей — нейросопроцессоре, он же NPU.
Когда речь заходит о мелком ARM64 компике, там каждый гиг наперечёт. Проц слабый, да и Nvidia видеокарту к малине / апельсину не прикрутишь. Тут на помощь приходят процессоры RockChip и встроенный в них NPU! Это не единственный нейроускоритель на рынке, но доступный по цене. В привычном мне окружении. Случайно натолкнулся на Orange Pi 3B. При относительно слабеньком проце у него аж 8 гиг памяти (обычно 1 — 2) и тот самый NPU на базе RK3566.
Чтобы появился стимул заниматься оптимизацией, нужно знать как (плохо) обстоят дела сейчас и как (хорошо) они могут обернуться по окончанию оптимизации.
YOLOv8 не сложно установить на x64 или arm64. Это python модуль, легко разворачиваемый менеджером пакетов pip.
Как есть, на моей custom модели, на CPU апельсина, задачи определения класса целого изображения, максимального для этой сети разрешения 224х224 пикселя, уже решаются в моём AllSky проекте. Для приведения к единому знаменателю я установил и запустил тот же детектор на Orange Pi 3B. Установил YOLO и классифицировал несколько изображений на модели, дотренированной на yolo8n-cls.pt.
Для поиска и определения объектов на (относительно) большой картинке (пример с фото части моей семьи в самом начале статьи) я использовал модель, дообученную от yolo8n.pt. Модель принимает 640х640 изображение на входе и (не без бубна) даёт на выходе набор координат боксов и их классы.
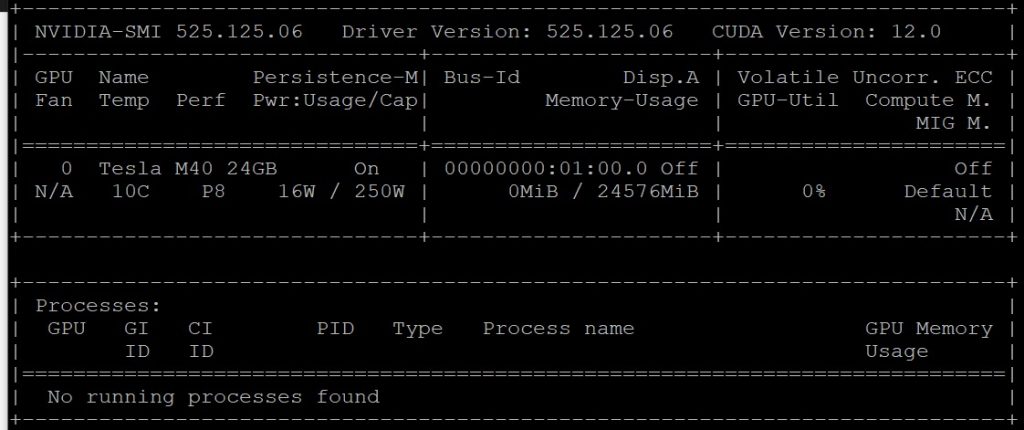
Опыт использования Nvidia Tesla M40 на компе говорил об увеличении скорости обработки на порядок. Я задействовал апельсиновый NPU, данные свёл в таблицы.
| Классификатор (224×224) | Детектор (640×640) | |
| CPU | 250мс | ~1500мс |
| NPU | 4.5мс (в 55 раз лучше!) | 46мс (в 32 раза лучше!) |
| Классификатор (224×224) | Детектор (640×640) | |
| CPU | 400% (4 ядра по 100%) | 400% (4 ядра по 100%) |
| NPU | 25% одного ядра (в 16 раз лучше!) | 28% одного ядра (в 14 раз лучше!) |
Входные данные: поток или одиночные изображения, расрешением 640х640 пикселей максимум.
Выход: набор координат боксов и их классы.
Что будет искать нейронка? Всё равно, честно сказать. Любой класс предметов живых или нет. Для примера выбрал лица членов моей семьи (а ещё добавил туда мордахи котов и собаки).
Поиск подходящих изображений
Я веду свой фотоархив с моего первого цифрового фотоаппарата, аж с 2004 года. Но, конечно же, лица людей меняются и я ограничился последними фотографиями. Терпения хватило отсортировать только фото за 2022-2024 годы.
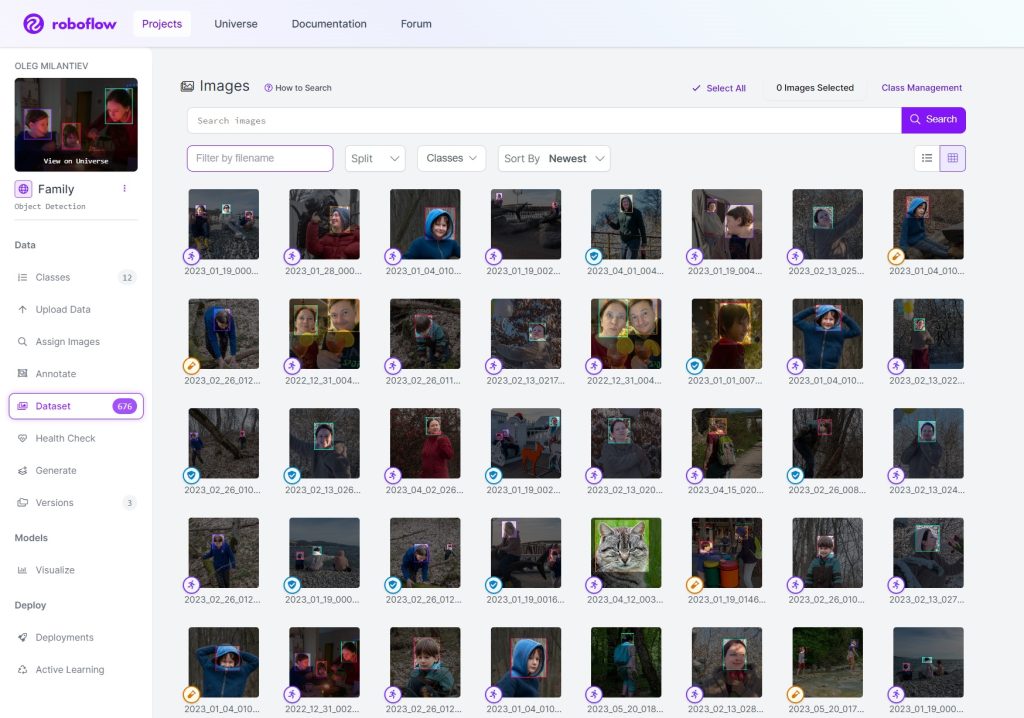
Пролистав все последние фото своего архива я выделил те, на которых попадается лицо члена семьи или мордаха животного. Это не портреты, чаще фото людей / зверей в том или ином окружении. Вот жена на фоне снега, вот дитё у водопада, вот сидит и зевает кот. Получилось 666 фоток с разным, но одинаково большим разрешением от FHD до 9 Мпикс. Загрузив по 66 штук за раз в фотошоп я откропил их с условием, чтобы в итоге получалось больше 640х640 и влезали все лица. Потом уменьшил до 640х640 и сохранил в жпегах.

Это … самая утомительная и бестолковая, но необходимая часть. Чем лучше датасет, тем лучше модель ресолвит. 666 фоток мало, честно сказать, но уж больно число ровное!
Отметка объектов для обучения
Есть много готовых инструментов разметки датасета, аннотации его изображений. Есть локальные, есть онлайновые (с кучей ограничений в бесплатной версии). Мне нравится roboflow. И ограничения не такие лютые, и инструментарий удобный. Да ещё и API простое есть. Тестовый ресолв присутствует. Помощник разметки новой версии датасета по модели из предыдущей. Шик!
Загрузил все фото датасета в roboflow и отметил всех Максов, всех Полинок, Юрцов, себя не забыл. Бабушку и дедушку, собаку и кошек. Занятие нудноватое, но мне показалось чуть интересней фотошопа. Сидишь себе, вспоминаешь классные моменты пары прошлых жутких лет.
Обучение нейросети
До какого-то размера бесплатно можно учить сеть и в roboflow. Но там куча ограничений, да и зачем-то, с пол года назад, я купил на aliexpress старую-новую Nvidia Tesla M40 аж с 24 гиг памяти. Стараю модель, но экземпляр карты новый. Под неё специально собрал комп на i3-8100 с 32 гигами памяти (больше не влезло). Поставил туда привычный мне Debian, драйвера Nvidia и настроил CUDA до работающего nvidia-smi.
import os
from roboflow import Roboflow
def project():
rf = Roboflow(api_key="мойключ")
return rf.workspace("oleg-milantiev-egsqq").project("family-yjije")
def download():
os.chdir('/mnt/goodwin/yolo/datasets')
dataset = project().version(4).download("yolov8")
def train():
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
model.train(data='/mnt/goodwin/yolo/datasets/Family-4/data.yaml', epochs=50, device=0, batch=128, imgsz=640, augment=False)
def upload():
version = project().version(4)
version.deploy('yolov8', '/mnt/goodwin/yolo/runs/detect/train')
#download()
#train()
#upload()Небольшая программа, если раскомментировать её последние строки, позволяет:
Последнее не обязательно. Но прикольно потом включить вебку или кинуть фото / видео в готовый детектор в roboflow universe. Обучение длится долго. Тем дольше, чем больше фоток, чем больше эпох, чем слабее видеокарта. Часы. Легко и дни на больших датасетах!
В папке ./runs/detect/train/weights получаем файл best.pt размером около 6 Мбайт.
Конвертация весов в формат RK NPU
Увы, как есть файл best.pt не подходит для использования в ресолве с участием нейросопроцессора RK3566. Необходимо файл весов сконвертировать в подходящий для этого NPU формат. Конвертировал на том же «большом» компе. Требования к ресам незначительные, время конвертации не критично.
Конвертация проходит в два этапа.
1 — Преобразование из pt в onnx
Нужна особая версия YOLO. Так как экспорт в onnx нужен какой-то то ли урезанный, то ли изменённый. Не сильно вникал на этом этапе исследования. Вот команды для установки окружения:
Конвертация pt -> onnx небольшим python скриптом:
from ultralytics import YOLO
model = YOLO('/mnt/goodwin/rknn/1-yolo/runs/detect/train/weights/best.pt')
path = model.export(format='rknn')Не смотря на команду export(format = ‘rknn’), после выполнения получаем best.onnx
2 — Преобразование из onnx в rknn
Чтобы не смешивать разные версии, я подготовил третье окружение на «большом» компе. Для его установки нужно скачать rknn_toolkit2 под x64 и установить. Вроде бы ничего сложного, но! В «интернетах» ходят тулкиты разных версий. По состоянию на конец февраля 2024 я видел 1.4.0, 1.5.0, 1.5.2 и 1.6.0. Мне кажется, показалось что видел 1.7.5, но утверждать не стану. И вот здесь есть важный момент выбора версии. Мне пришлось перебрать все, чтобы понять, что на моём RK3566 при использовании YOLOv8, одинаково подходят только 1.5.0 и 1.5.2. Выбрал 1.5.2, как чуть новее.
Важно, что проверять надо не только получится ли файл best.rknn (всегда получится), но и запустится ли пример с этой версией базы и с соответствующей версией rknn_toolkit_lite на апельсине! Если база сконвертирована под 1.4.0, то и lite нужен 1.4.0!
Для конвертации, без изменений, подходит скрипт convert.py из https://github.com/airockchip/rknn_model_zoo/tree/main/examples/yolov8/python.
Чтобы конвертация с квантизацией до int8 прошла, необходимо:
Вуаля, получаем файл best.rknn. Его несём на апельсин!
Использование custom модели на RK3566
Ну и собственно, зачем всё выше делалось? Чтобы взять файлик и быстро найти на нём все мордашки из примера:



Как уже упомянул, для ресолва на arm64 потребуется не rknn_toolkit2 (только для x64), но rknn_toolkit_lite2 (только для arm64) именно той же версии, которая была использована при конвертации. На самом деле я случайно успешно запустил в toolkit_lite2 версии 1.5.2 модель, подготовленную на 1.5.0. Но лучше пусть версия полностью совпадает.
После установки Ubuntu 22 с апельсинового сайта, в /opt появилась папка со скомпиленным C++ тестом базовой модели YOLOv5. Не уверен, нужно ли дополнительно качать librknnrt.so или он установится сам при установке Python модуля. Переставлять ОС пока лень. Так что опишу всё мною проделанное с надеждой, что кто-то в комментах поправит меня, если я перечислил лишнее.
Здесь лежат дистры Python пакета rknn_toolkit_lite2-1.5.2-cp310-cp310-linux_aarch64.whl под разные версии Python (у меня 3.10). В последней версии git репо тулкита, по состоянию на конец февраля 2024, лежит версия 1.6.0. Найти другие можно в том же репо, переключившись на нужную ветку / коммит:
Установка простая:
Базовое использование тоже не сложное:
from rknnlite.api import RKNNLite
import cv2 # opencv-python
rknn = RKNNLite()
rknn.load_rknn('best.rknn')
rknn.init_runtime()
img = cv2.imread('1.jpg')
result = rknn.inference(inputs=[img])
print(result)Казалось бы всё? Ан нет… каждая сетка выдаёт свой результат в виде тензоров (многомерных массивов) неописанной структуры. Просто набор float в кууууче таблиц. Пойди разберись, где ответ и что с ним делать.
Ответ на этот сложный вопрос лежит в файла yolov8.py в той же model_zoo, где был найден convert.py. Кроме файла yolov8.py понадобится папка py_utils в корне этого git репо. И установка torch средствами pip install.
UPD: ChatGPT-3.5t написал короткую функцию DFL без torch 🙂 . В идеале эту часть вовсе стоит взять из C++ примера.
Собрал (и буду доделывать) пару ROS2 пакетов. Обновлять их буду в github проекте своего бота: https://github.com/oleg-milantiev/ros2-vedrus.
Пакет yolov8_interfaces содержит пару интерфейсов, то есть типов сообщений:
Пакет yolov8_rknn, его единственная нода solver, принимает параметр model с путём до того best.rknn, который мы получили выше. Модель загружается в память при старте. Нода слушат входные топики (image_raw разных камер). Текущая версия поддерживает одну камеру, но так как их у меня на столе две, то это изменится на днях. Найденные объекты публикуются в выходной топик. В заголовке сообщения указывается ID камеры.
header:
stamp:
sec: 1708893459
nanosec: 294002895
frame_id: inference
yolov8_inference:
- class_name: max
score: 0.60594245046377182
top: 100
left: 482
bottom: 196
right: 559Ещё я планирую для каждой камеры ввести параметр rate. Он будет задавать делитель, как часто нужно анализировать входные кадры. Допустим, камера публикует 5 fps сообщения в очередь /cam1/image_raw. При rate = 1 каждое сообщение будет обработано. При rate = 5 ресолвиться будет каждое пятое сообщение, максимальная частота выходящих от солвера сообщений будет 1 в секунду. Ещё есть мысль ввести адаптивный алгоритм, корректирующий rate в зависимости от загрузки CPU / NPU.
Загрузка проца при анализе каждого кадра от старой вебки, работающей в разрешении 640х480 на 5 fps — около 30% (одно ядро, то есть по шкале в 400% максимум), если объекты не найдены с пиками до 40% при найденных 1..3 объектах. Полагаю, для сглаживания и улучшения характеристик произвольности, со временем я перепишу часть обработки выходного тензора из-под yolo на C++.
А ещё я написал ноду, которая с помощью анализа найденного, формирует тревоги и предупреждения, находя азимут объекта и пробует понять расстояние до него. Весь код у меня в гите, репо ros2-vedrus.
Собрал видео по тексту. Как мне кажется, получилось интересно!
Круто. Очень круто. Я подписываюсь на блог)
Класс! Интересно как получилось преобразовать и запустить модель классификации
А какую ОС с поддержкой драйверов NPU устанвливали?
Штатную убунту с сайта orange pi. Там сразу примеры в /root лежат.